
Depuis un an, j'ai créé une série de projets avec et autour de l'IA : agents pour trouver des idées de contenu, serveurs MCP, scripts qui qualifient des données, automatisations.
Je suis de plus en plus confronté à l'explosion des coûts de tokens. Les abonnements à Claude où Codex ne suffisent plus, les coûts API sont pour certains modèles exhorbitants (Opus je parle de toi...).
C'est pourquoi j'ai testé si l'IA en local pouvait être une bonne alternative. J'ai installé LM Studio, chargé Gemma 4 de Google, et branché le tout sur un petit POC interne de prospection. Voici ce que ça a donné.
LM Studio : faire tourner une IA locale sans toucher au terminal
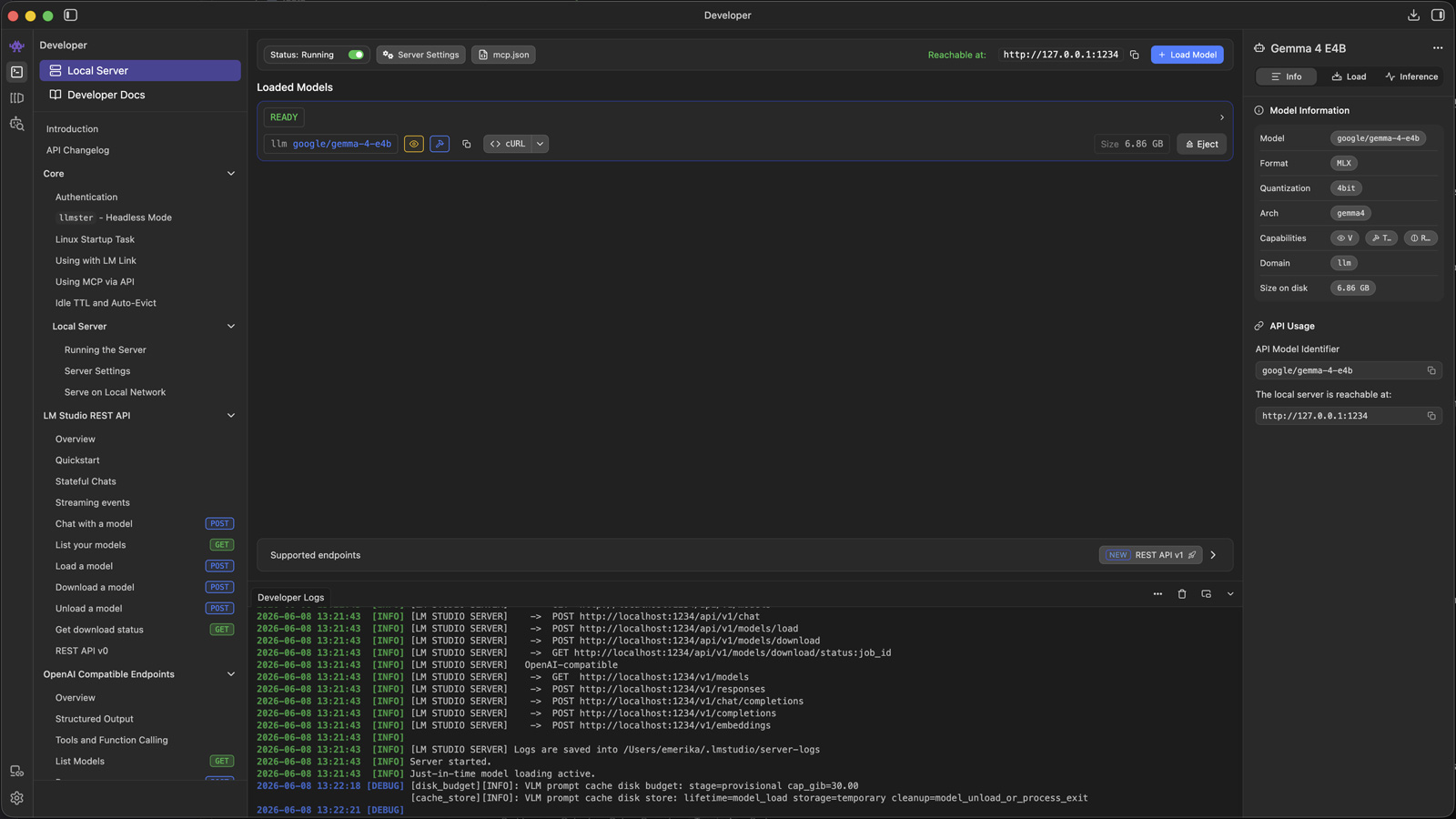
LM Studio est une application desktop gratuite (Mac, Windows, Linux) qui permet de télécharger et faire tourner des LLM open source. Pas de ligne de commande, pas de Docker, pas de Python à installer.
L'interface est simple :
- Un store de modèles intégré (connecté à Hugging Face) pour télécharger Llama, Mistral, DeepSeek, Qwen, Gemma…
- Une interface de chat pour discuter directement avec le modèle chargé.
- Un serveur API local compatible OpenAI que l'on active d'un clic.
C'est ce dernier point qui m'a fait choisir LM Studio. En cochant une case dans l'onglet Developer, LM Studio expose un serveur sur localhost:1234 au même format d'API que celui d'OpenAI. C'est aussi simple qu'efficace. Une app codée pour appeler ChatGPT peut être redirigée vers le LLM local en changeant juste l'URL de base.
Pourquoi Gemma 4 de Google

Côté modèle, j'ai choisi Gemma 4, sorti début avril 2026 par Google DeepMind, sous licence Apache 2.0. La famille Gemma 4 propose plusieurs déclinaisons selon la machine qu'on a sous la main :
- E2B (2,3 milliards de paramètres effectifs) : pensé pour le mobile et l'edge.
- E4B (4,5 milliards) : un bon équilibre pour un laptop standard.
- 12B Unified : multimodal (texte, image, audio).
- 26B A4B (Mixture-of-Experts) : 3,8B de paramètres activés par token, pour du raisonnement plus avancé.
- 31B Dense : la version la plus capable, à réserver aux machines costaudes.
Sur mon MacBook Pro 2023 avec 36 Go de RAM, j'ai testé et pu faire tourner correctement les versions E4B et 12B.
Sur la qualité, soyons honnête : Gemma 4 ne remplace pas un Claude Opus ou un GPT sur du raisonnement complexe ou de la rédaction longue. Mais sur des tâches ciblées et répétitives (classer, extraire, scorer, résumer), les réponses sont propres et la latence reste correcte.
Le test : brancher une web app de prospection sur l'IA locale
Au-delà du chat hors-ligne, ce qui m'intéressait surtout, c'était l'intégration applicative. Connecter l'IA locale à une application web, tâche où j'utilise d'habitude un modèle cloud comme GPT, Gemini ou Sonnet. Pour ce test, j'avais en tête un POC interne : une web app de prospection qui récupère des leads et les qualifie via l'IA.
Le besoin est classique :
- Récupérer une liste de leads (nom de l'entreprise, secteur, taille, site web).
- Demander à un LLM de scorer chaque lead selon des critères que je définis.
- Catégoriser les leads et prioriser les meilleurs.
Sur quelques centaines de leads par jour, faire ça avec l'API d'OpenAI ou de Claude commence à coûter quelques euros par jour, multipliés par 365. Avec une IA locale, le coût marginal tombe à zéro.
Le workflow technique a été simple :
- J'active le serveur API dans LM Studio.
- Dans ma web app, je remplace l'URL d'OpenAI par
http://localhost:1234/v1dans le client SDK. - J'envoie mes prompts de qualification exactement comme avant.
- Gemma 4 me retourne un score et une catégorie au format JSON.
Bluffant de facilité, tant que LM Studio tourne j'ai une intelligence artificielle exploitable, avec ou sans internet. Et accessoirement, les données des prospects ne quittent pas ma machine, ce qui est confortable côté RGPD.
Les limites que j'ai rencontrées
L'IA locale n'est pas magique, et il y a quelques bémols à connaître :
- Il faut une machine puissante. Mon MacBook 2023 avec 36 Go de RAM tient bien, mais sur un laptop d'entrée de gamme, on est limité aux petits modèles.
- La latence reste supérieure à un appel API cloud sur un modèle équivalent, les data centers ayant des GPU autrement plus puissants.
- Les modèles open source ne rivalisent pas encore avec les modèles frontier sur les tâches complexes. Pour de la qualification de leads, c'est largement suffisant. Pour coder je continue d'utiliser Codex et Claude Code.
Pour moi, l'IA locale n'est pas un remplaçant universel des APIs cloud, mais un complément pour des cas d'usage précis.
Pourquoi je pense que ça va devenir un standard
Malgré ces limites, je pense que l'IA locale va prendre une place de plus en plus importante dans les années qui viennent. Quelques raisons :
- Les coûts cloud explosent. Les nouveaux modèles sont de plus en plus chers (Gemini Flash et sa dernière version par exemple), et les abonnements Pro sont de plus en plus limités en tokens. Internaliser une partie des traitements répétitifs devient économiquement intéressant.
- Le hardware grand public progresse. Ce qui demande aujourd'hui un MacBook Pro M3 avec 36 Go tournera probablement dans quelques années sur une machine d'entrée de gamme. Les puces grand public intègrent de plus en plus des processeurs dédiés à l'IA.
- Les modèles open source progressent vite en rapport qualité/taille. Gemma, Llama, Qwen, Mistral comblent une partie de l'écart avec les modèles fermés.
- Le sujet des données. Pour les secteurs sensibles (santé, juridique, finance, RH), envoyer ses données chez OpenAI ou Anthropic est juridiquement compliqué. L'IA locale règle une partie du problème.
Le pattern qui me semble se dessiner, c'est un mix : modèles locaux pour le volume et les tâches répétitives, modèles cloud pour la complexité et le raisonnement avancé. Le bon outil pour le bon usage.
Conclusion
Cette première immersion dans l'IA locale m'a donné envie de creuser le sujet. LM Studio rend l'installation et la mise à disposition d'une API locale très simples, et Gemma 4 est suffisamment capable pour des tâches ciblées comme de la qualification de leads.
Sur mes prochains projets qui demandent du volume sur des tâches répétitives, l'IA locale fera clairement partie des candidats pour ma stack.
Et vous, vous avez déjà chiffré ce que vous coûtent vos appels IA cloud, et testé un setup local ?
📌 Si vous souhaitez réfléchir à la place de l'IA (locale ou cloud) dans votre produit, découvrez mes services de Product Engineering.